1. 背景
首先介绍了AI安全的意义,或者说是对AI模型/算法进行检测的意义。
这一部分提到了自动驾驶对AI模型安全的依赖性,以及对抗样本攻击对图像分类的影响,因此必须要注意AI模型的鲁棒性。


为什么用Fuzz来结合AI安全测试呢?
现有的AI测试方法有诸多不利和限制:
- 对于白盒测试来说,白盒测试本身需要一些复杂繁重的操作,且需要获取到源码才可以测试,费时费力;
- 现有的黑盒测试法变异inputs直到出现问题,非常消耗时间,而且极其依赖人工标注的数据集标签;
- 其他的工作则是神经元覆盖率不足。
- 还有一个著名的方法:DeepXplore,但是该方法依赖于Cross-referencing,而在实际操作中,该算法的可扩展性不强,毕竟寻找类似的可以cross-referencing的DL系统是一件很难的事情。

笔者在本文提出了DLFuzz,基于模糊测试和DL测试有着相似的目标,即实现更高的coverage从而获得更多的exceptional behaviors。本文将fuzz测试的关键部分结合到对DeepLearning测试中:
- 优化目标(Optimization Goal)。达到更高的神经元覆盖率和暴露更多异常行为的目标可以看作是一个联合优化问题,该优化问题可以以基于梯度的方式来实现。
- 种子维护(Seed Maintenance)。Fuzz时,基于在后续模糊中持续提高神经元覆盖率的潜力,导致神经元覆盖率一定增加的突变输入被保留在种子列表中。
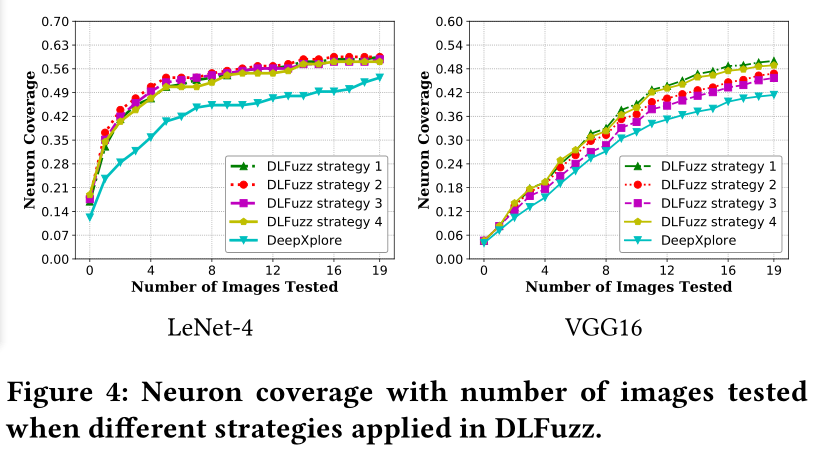
- 变异策略的多样性(Diversity in Mutation Strategies )。本文设计了许多神经元选择策略来选择从而可能覆盖更多逻辑和触发更多神经元的错误输出。测试输入的多种变异方式已经实现,并且易于集成。
2. 实现方案
DLFuzz的过程,真的很简单粗暴但有效:
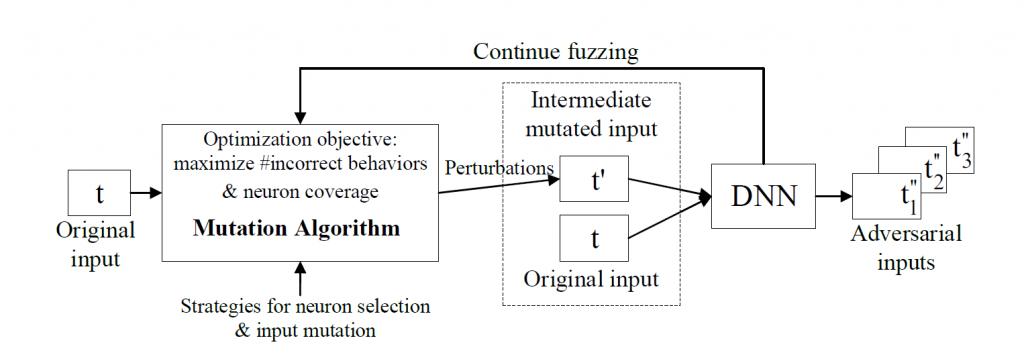
DNN是待测神经网络,比如我们用VGG16做图像分类。
Mutation Algorithm 将输入的待分类图片t进行微小的变化,这种变化是肉眼不可见的,生成t’作为输入进入神经网络。
若t’被当做另一个标签分类,则认为这是一种异常行为且该样本可以被认为是对抗性样本。
2.1 Mutation Algorithm
DLFuzz的变异部分是通过解决一个联合优化问题来完成的,即最大限度地提高神经元覆盖率和不正确行为的数量。,这是因为从逻辑上来说,覆盖更多的神经元有可能引发更多的逻辑和更多的错误行为。
DLFuzz在神经元的coverage的定义和计算上和DeepXplore采用一致的方式,那些输出大于设定阈值的神经元被认为是激活了,或者说被覆盖到了。

Algorithm 1
Gradient-based Adversarial deep learning 往往优于其他方法,特别是在时间效率上。它通过优化 inputs 以最大化prediction error来发现perturbations,注意这与在训练DNN时优化权重以最小化prediction error相反。所以要通过定制Loss Function并通过梯度上升使Loss最大化,不难实现。
Fuzzing Process:
模糊测试过程说明了算法1的整体工作流程。当给定一个测试输入 $x$ 时,DLFuzz维护一个seed_list[ ],用于保存input_list[ ]变异的输入。
起初,种子列表中只有一个 $x$ 作为输入。接下来,DLFuzz遍历每个种子 $x_s$ 并获得构成其优化目标的元素。
然后,DLFuzz计算出梯度方向,用于以后的Mutation。
算法line9:是DLFuzz的损失函数,如下:
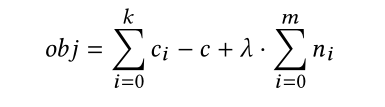
对于这个公式:多项式第一项中 $c$ 是输入的原始类标签,$ci (i=0, …, k)$ 是置信度仅低于$c$的前k个类标签之一(Line7)。
DLFuzz将处理后的梯度作为扰动反复应用,并获得中间输入 $x′$。
每次突变后,获得中间类标签$c′$,覆盖率信息 cov_tracker,$x$和$x′$的 $l_2$ 距离。如果希望通过 $x′$ 和 $l_2$ 距离提高神经元的覆盖率,$x′$ 将被添加到种子列表中。最后,如果 $c′$ 已经与$c$不同,则种子$x$的突变过程结束,$x′$ 将被纳入对抗性输入的集合。
因此,DLFuzz能够为某一原始输入生成多个对抗性输入,并探索一种新的方式来进一步提高神经元的覆盖率。
2.2 Strategies for Neuron Selection:
- 选择过去测试中经常涉及的神经元;
受传统软件测试的实践经验启发:经常或很少执行的代码片段更有可能引入缺陷。经常或很少覆盖的神经元可能会导致不寻常的逻辑,并激活更多的神经元。
- 选择过去测试中很少涉及的神经元;
- 选择权重最高(尽可能高)的神经元;
作者推断weights越高对其他神经元影响越大。
- 选择靠近激活阈值的神经元。
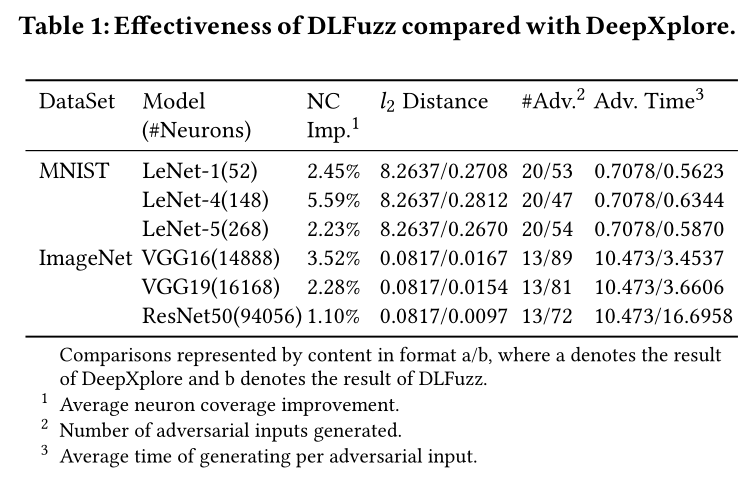
3. 实验与结果
和DeepXplore一样,DLFuzz 给每个数据集都测试了三种 pre-trained models:
- LeNet-1, LeNet-4, LeNet-5 for MNIST;
- VGG-16,VGG-19, ResNet50 for ImageNet.