
The LLVM framework applies some optimizations to construct its internal Dependence Graph [5], such as considering strongly connected components as a single node (the so-called P-Node).
Code:
https://github.com/elManto/DDFuzz
在AFL基础上引入 data dependency graphs(DDGs)

1. 背景/出发点
作者认为DDGs中的信息可以为fuzzer提供一个CFG无法捕捉到的额外的feedback
作者基于AFL++和LLVM,在Fuzzer通过CFG奖励的同时,在探索新的DDG edge的时候也会得到奖励——DDFuzz
1.1 数据依赖图 Data Dependency Graphs
介绍link→传送门
2. 实现 Methodology and Implementation
借助LLVM pass实现,版本LLVM13
选择LLVM的原因:首先,中间表示IR是 静态单赋值(Single Static Assignment,SSA)形式,这意味着每个变量只分配一次,所有变量必须在第一次使用之前定义, 这简化了与允许使用多个定义的其他代码表示相关的LLVM IR变量之间的依赖关系的恢复;其次,LLVM工具链已经很好地集成到流行的Fuzz项目中,因此新解决方案可以很容易地在现有的Fuzz技术中实现。
DDFuzz实现过程将分为三个主要部分: DDG构建、依赖过滤和目标检测。
2.1 DDG构建
实现静态分析部分时,首先要选择合适的LLVM IR变量来构建数据依赖图。最直观的方法是通过依赖 def-use edge 来表示依赖关系,来恢复LLVM IR中出现的每个变量的依赖关系。然而,作者注意到,这种技术并不适合该技术的应用环境。这是因为IR的SSA形式会产生太多的依赖关系,反过来将导致fuzzer的反馈不佳,执行目标二进制文件时将产生巨大的开销。
LLVM 框架本身可以构造 internal Dependence Graph, 例如将强链接的组件作为单个节点 (strongly connected components as a single node (P-Node))。本文将这个称为$DDG_{raw}$。
作者认为应该只考虑only a subset of LLVM variables,也就是LLVM变量中的一个子集而并非全部,关注这些变量的定义和使用(引用),并且这样就只需要恢复和这个子集相关的数据依赖关系。首先对于二进制形态的文件而言,数据流实际上只在内存读写的时候的发生。在IR层面上来说,使得作者将指令的Load和Store作为数据流的Source和Sink。本文在此基础上还增加了Call指令,用于跟踪变量的使用,比如,我们可以跟踪函数调用参数的依赖关系。最后我们使用Alloca指令作为def-use edge的潜在的source。尽管编译器在优化过程中会将很多Alloca指令优化掉,但是他仍是有效的。
如下Algorithm 1就是本文的解决方案,其中最主要的两个数据结构分别是:
- DDG本身(a map of sets)
- 一个被称为Data Flow Tracker (DFT)的数据结构,在算法开始时也初始化为集合映射。

就上图伪代码,blocks是所有bb的集合,通过GetBasicBlocks()得到;同理instructions是单独bb下的所有指令的集合;
8行的IsDefinition()函数判别该指令是否为def指令即 Load 和 Alloca,若返回为true则将指令 i 对应的value添加到DFT中的一个新的条目;
对于一般的指令(11行IsGeneric()),也就是那些既不是Sourse也不是Sink的指令,一般提取value和操作数ops即可,然后介绍了InsertDataFlow()这个原语,但是没懂什么意思:The primitive InsertDataFlow is then responsible to track the fact that the return value is actually depending on the operands variables,大概好像是说value与ops相关。
接着我们将Getuse()得到的指令(其实就是那些use instructions)遍历,用QueryDataFlow()也是一个原语,用于迭代DFT中的key寻找u(use instructions)所对应的集合中的元素,从而找到u所依赖的全部定义。最终输出一个数据依赖图,其中的边edge连接变量D的定义def和依赖于D的变量的使用use,本文称该类型的DDG为DDG_{Full}。
按照我对DDG_{Full}的理解,举例如下:
int a = 1; //A
int b = 2; //B
int c, d; //C1 C2
c = a + b; //D
d = c + a; //E语句E中涉及到c的使用,所以在DDG中会连接到c的定义,以及c所依赖的所有比如a和b的定义。
2.2 Filtering 过滤器
本文考虑的目标是轻量地对编译后的二进制文件进行分析,因此引入优化Optimizations和过滤器Filter减少插桩数量。Filters会过滤掉不会给Fuzzer反馈的edge。那么首先由于本文的基本粒度是bb,那么bb内部的依赖关系都可以被过滤掉。类似的,连接同一对bb的多个依赖关系应该被合并为一个。
DDG覆盖插桩的目的不在于帮助fuzzer到达多层嵌套的代码位置,而是在这条路径涉及到的依赖中尝试找到新的程序位置(覆盖位置),或者说想在已有的分支中触发到新的路径新的分支,通过探索这些新的来发现程序新的flaws。所以插桩
实际上本文实现了两个主要的过滤规则来过滤掉冗余的数据依赖关系。
- 规则一:检查一个依赖项是否在两个相连的基本块之间,也就是说其中一个bb是在CFG中另一个的后继bb。在这种情况下,依赖项不会添加任何尚未被边缘覆盖捕获的附加信息,不然只会增加开销还不会向模糊器提供任何有用的反馈。因此这种情况下,本文丢弃这些数据流。
- 规则二:扩展了规则一,涵盖了一些其他的情况,比如其中数据依赖关系已经被边缘覆盖抓取到。 这里又定义说明了两个额外的数据流:
- 一个变量的使用U取决于唯一的(Single)定义D,这个定义可以在U的许多个基本块之前被找到。在这种情况下,本文注意到没必要在数据结构中保留两个bb之间连接的bb,因为根据def来说,如果程序到达了(够到了reach)U所在的代码块,就意味着一定已经经过了D(因为这是唯一定义)。这时候传统的edge coverage insrumentation在通过这条路径的时候已经奖励了fuzzer,所以对于这种的数据流本文选择不跟踪且从DDG中丢掉。
- 另一种则是一个变量的使用U取决于多个定义(More than),比如 φ-node variable。用下图举例,黑线表示CFG中的edge,蓝线为DDG的edge。这时fuzzer达到100%的edge coverage但是两个def-use对中只有一个会被触发。这里的原因是记录edge coverage的机制,比如将现在的和之前的BB的异或(XOR),所以执行execution总是用同一条路径到达use,fuzzer也不会将这两条路当做两个单独的发现。所以本文决定唯一保留这种类型的数据流。
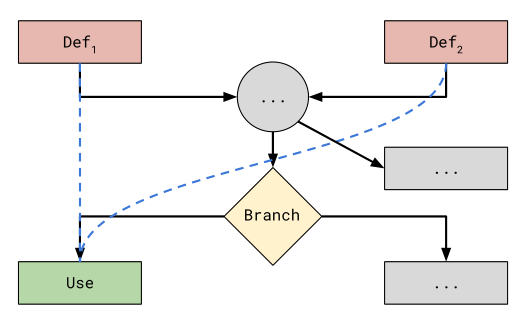
过滤后的DDG称为$DDG_{filter}$,在这个图中,只包含def-use关系的flows,且对于同一个变量的use应该至少有两个def。
2.3 DDFuzz的插桩 Instrumentation
如上节所说,基于AFL的Fuzzer往往通过计算当前和之前位置的IDs的异或值XOR记录一个edge visit,该异或值还被用作一个index索引以访问一个存储着某一个edge被hit的次数的bitmap,这种方式被保留下来继续使用。
但是在DDG中这个方式并不适用,因为XOR中的两个输入的位置并不连续,且执行在到达数据依赖的use时会经过多个bb。本文为解决这个问题,给每个包含可能被track的def的bb都设置了一个额外的变量,开始为0。当reach到这个bb,instrumentation会将这个marker value改为bb的ID。最后,通过生成一个新的位图索引,用目标块的ID表示相应的marker value。由于$N⊕0 = N$,结果将只考虑实际执行的定义,因此当通过不同的数据流路径到达相同的基本块时,会产生不同的值。
举个例子吧,太抽象了这个东西:高亮为IR级别插桩代码。

3. 评估 Evaluation
该部分也应该作为阅读的重点,甚至说好的论文没有废话,尤其对我这种刚入门fuzz的来说。我需要尽可能的了解业内常用的评估标准、工具、数据集还有一些基础的常识知识。
使用了3个dataset:
- dataset1 是10个包含漏洞的真实的开源项目的旧版本,而且将分为两组:根据经验分为强数据依赖型和弱数据依赖型,为不同类型不同倾向的代码集合。
- dataset2 采用了Fuzzbench,因为有很多bug且应用很多,程序量也很大。一共有22个不同的程序。 竞品:LAVA-M;MAGMA;
- dataset3 源自一个较新的论文,有6个应用程序。传送门:Tim Blazytko, Cornelius Aschermann, Moritz Schl¨ogel, Ali Abbasi, Sergej Schumilo, Simon W¨orner, and Thorsten Holz. GRIMOIRE: Synthesizing structure while fuzzing. In 28th USENIX Security Symposium (USENIX Security 19), pages 1985–2002. USENIX Association, August 2019.
3.1 实验结果 dataset1
效果对比(强弱数据类型):
首先是针对性地选取了的10 个项目,通过编程经验将它们分为强数据依赖型(上)和弱数据依赖型(下)两类,如 Table1所示
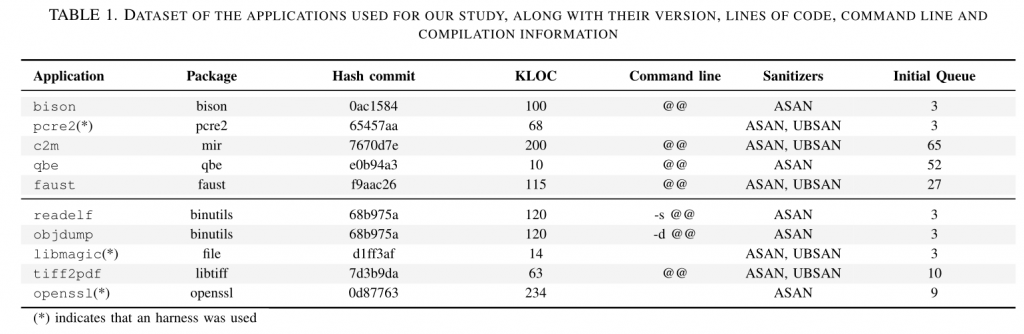
作者使用了 AFL++ 进行了对比实验。首先,作者计算了被插桩的基本块占所有基本块的比例(即DD ratio)这一参数,用数据证明了他们区分两类项目的合理性。
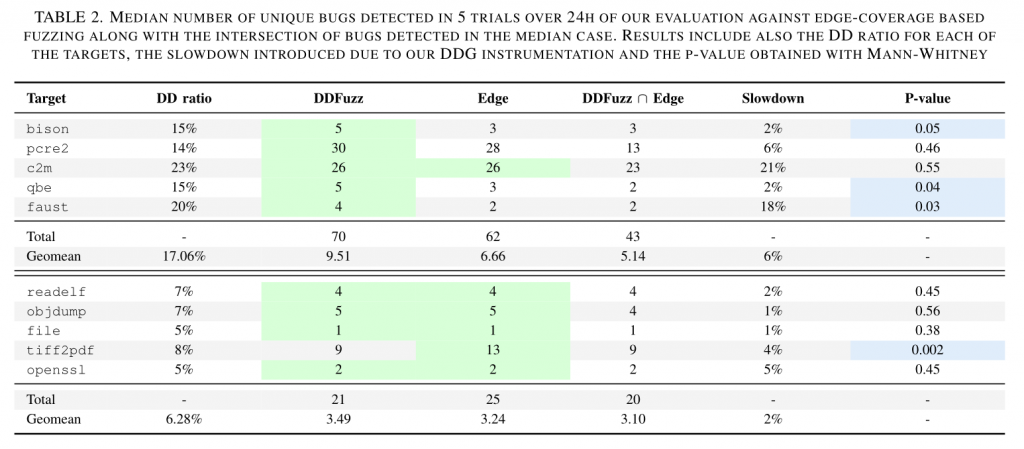
从 TABLE 2 中可以看出,在强数据依赖型项目的漏洞检测上,DDFuzz 比传统的覆盖率导向的 Fuzzer (Edge)表现更好。进一步,对两种 Fuzzer 检测出的漏洞进行去重和对比,作者发现 DDFuzz 还能检测出很多之前发现不了的漏洞。但在弱数据依赖型项目上,DDFuzz 则表现欠佳。
之后,作者通过计算Mann-Whitney U test(曼-惠特尼U检验/曼-惠特尼秩和检验)中的 P-value ,统计分析并证明了,DDFuzz 的表现受项目本身数据依赖关系的影响很大,当分析项目为弱依赖型时,DDFuzz 和 AFL++ 差别不大。
性能开销的分析:
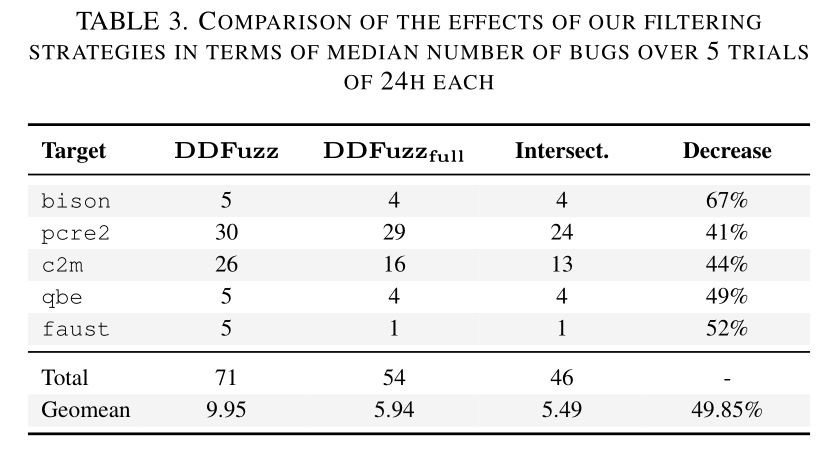
作者主要关注其依赖关系过滤策略的有效性,将 DDFuzz 使用的 DDG 与由 LLVM 生成的 DDG 和过滤之前的 DDG 进行对比。作者发现其他两类 DDG 由于其开销过大,很容易触发 AFL++ 的超时机制,而经过剪枝(过滤)后的 DDG 降低了插桩数量,从而提高了程序的执行速度。
插桩方式对比:
此外,作者还将 DDFuzz 使用的插桩方式和其他插桩方式(Ngram2,Ngram4 和 Ctx)在漏洞检测和代码覆盖率上的表现进行了对比。作者发现,尽管不存在某个检测漏洞最多的插桩方式,但 DDFuzz 的优势在于发现不同的漏洞。而在代码覆盖率上,DDFuzz 则表现一般,只取得了比 AFL++ 更好的结果,但这和作者设计 DDFuzz 的预期也是符合的。
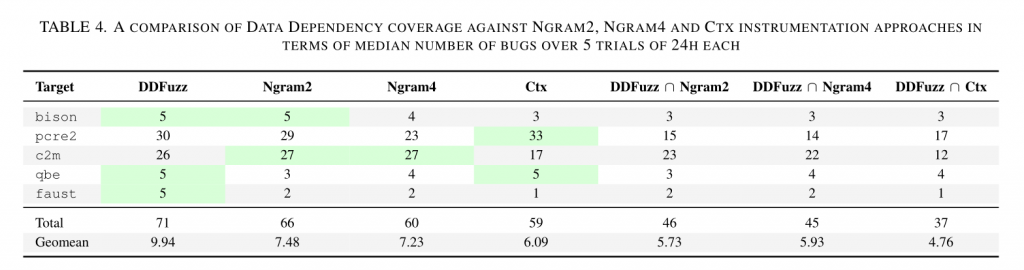
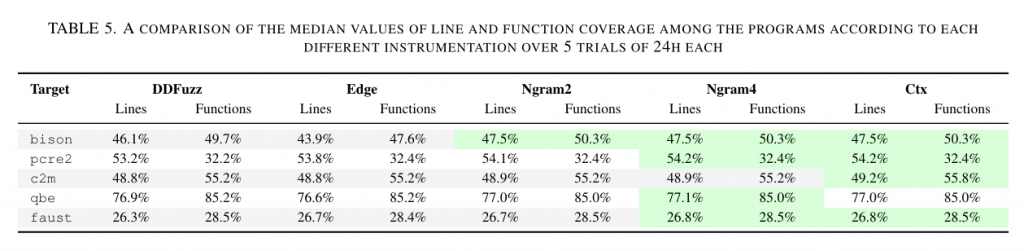
3.2 实验结果dataset2 – FuzzBench
作者随后将 DDFuzz 和 AFL++ 都放到了 FuzzBench 上进行测试,发现 DDFuzz 只有在发现漏洞数目的几何平均(Geomean)数上表现得更好,从整体发现的漏洞数目来看则逊于 AFL++ 。但具体到某个项目上,作者仍然证明了 DDFuzz 具有发现不同漏洞的优势。同时,作者还手动统计了这些项目的 DD ratio,验证了其作为区分强/弱数据依赖型项目标准的合理性。

最后,作者对 DDFuzz 挖掘出的漏洞类型进行了分析:
相比于只使用 AFL++,DDFuzz 更容易发现缓冲区溢出类漏洞,如下表:
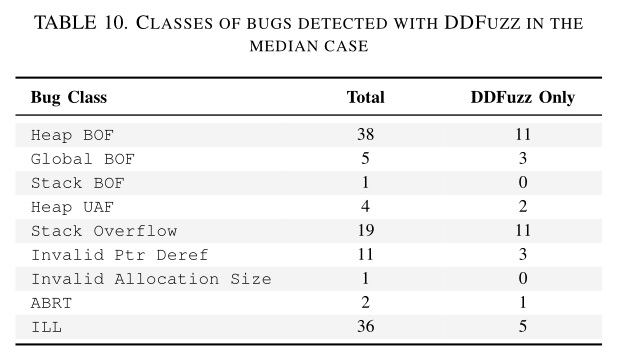
作者还统计了关于数据集三的结果,并抽取了 tcc 中的一个漏洞作为样例分析
Final:
Q:基于AFL的Fuzzer往往通过计算当前和之前位置的IDs的异或值XOR记录一个edge visit我自己看AFL的時候怎麽沒注意?
