
文章Arxiv链接:AI Agents Under Threat: A Survey of Key Security Challenges and Future Pathways
写在前面 关于先前的断更
很久没有更新了,自从来了澳洲之后就很少继续更新自己的博客,也很少沉淀下来去写点什么东西。以前还是个本科生的时候,感觉写东西的期求还没有那么大,写点基础知识即便不全面也就罢了,现在却希望有所输出,希望自己能输出观点上的产出和一些新的看法,从这个角度来看确实是成长了一点。另一方面的原因也是因为研究节奏快,因为现在主要在做大模型安全相关的研究,大模型本身就更迭的很快,赶论文都要赶不上了哪还有时间沉淀自己动不动就更新博客呢?
但是我也见识到了对我个人而言的“缺少记录和输出”的弊端,这个博客看的人很少,倒也不指望有什么交流,仅有的一些给我发过邮件的其实都是想借鉴一下我的代码用以应对学校的作业或某些研究项目。写博客这个东西更多是给我自己看的,有时候回头看一眼,就能发现曾经的自己的不足之处和可以吸取到的教训,确定自己在学习这个领域上确实是在向前走的,我会得到莫名的成就感和鼓舞,这是我的学习动力一大来源,非常重要。
最近我深刻发现了一些学习与工作上的一些问题,包括我自己的心态的问题。我总是抱着一种心态就是“哎呀这个工作做完了就好了”, “哎呀就忙过这一阵就可以做自己想做的事了”,但是事实上所有的事情都不是一蹴而就的,即便有时间我也无法立刻在那一点间隙里做完所有要做的事,而事实上手头的事情也不是可以真的能100%按照自己心中所想向前推进的,我无法保证真的会有那么一个留给我自己的“间隙”,于是我陷入了无穷无尽的内耗。
内耗程度严重到感觉自己已经不是一个年轻人了,才24岁“刚过青春期”,却每天活的像个35岁的状态,甚至一度怀疑“这PhD真的是我应该做的吗”,但是我后来也想明白了,所有的事情都可以同步去做,尽力就好了,而不是一定要成功。因此我还是希望,我能多更新一些博客也好,GitHub的兴趣,甚至一些其他的爱好,活得像Kisna一点,而不是逐渐迷失自己。
关于Survey
这是一篇与天津大学和蚂蚁集团的合作的Survey文章,主笔人为Mark,主要围绕着AI Agent的安全问题展开的调研和review。
容我小吹一波,个人认为本文写的内容——LLM Agent现存的安全问题 还是比较全面的,我们一共查阅了应该几百篇相关领域的paper。截止于文章发布在arxiv的时间,这些文章主要还是集中于LLM本身的安全问题,包括且不限于LLM的Membership Attack,Jailbreak,以及其他的衍伸的攻击。就LLM本身的安全来说,我个人认为攻击面是有限的,考虑到最先进的ChatGPT(例如当下的GPT4o)唯一的input只有prompts,虽然现在是多模态的输入,但是这种狭窄的攻击面带来的更多是“现象级的”研究文章,换句话来说,就是更新一个版本(添加一个新功能)就会多一些之前没有被发现的漏洞(prompt attack,jailbreak之类),但是这种漏洞被发现后极易被修复,对于开发者来说最简单的办法不过是加一层filter即可,可以加在prompt输入的时候,也可以放在模型返回response的阶段。因此,这种漏洞和安全问题我认为意义不是特别大。
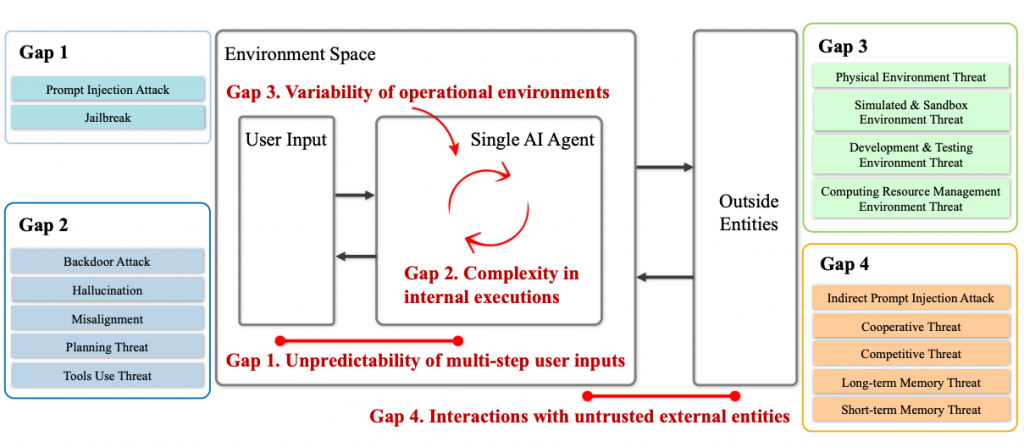
然而,对于LLM Agent来说,攻击面瞬间广泛了很多,就直觉来说,我们理想情形中的Agent应该可以自动或者听从指示自动的获取信息并作出决策,最后做出行为。这相对于普通的聊天机器人式的LLM有着巨大的扩展(也因此需要一定时间的发展,尚不成熟),因此我们为了便于理解和定位安全问题,文章里将整个AI Agent的Workflow划分成了Environment,User Input, Single AI Agent和Outside Entities。上图主要是为了突出现有关于AI Agent Sec的survey仍有一些没有说明的gap需要得到补充,这也可以算是我们的motivation了。
为了说明每一部分的gap和安全问题,如图(我画的,好看吧==),并且根据不同的攻击类型对其进行了分类,下图的流程应该相比较于上图更直观一些,尤其是我们将AI Agent内部的推理归因以及计划的行为按阶段表现出来,这是因为每一个阶段性行为都可能会对应我们传统的一般的LLM的一些安全问题。
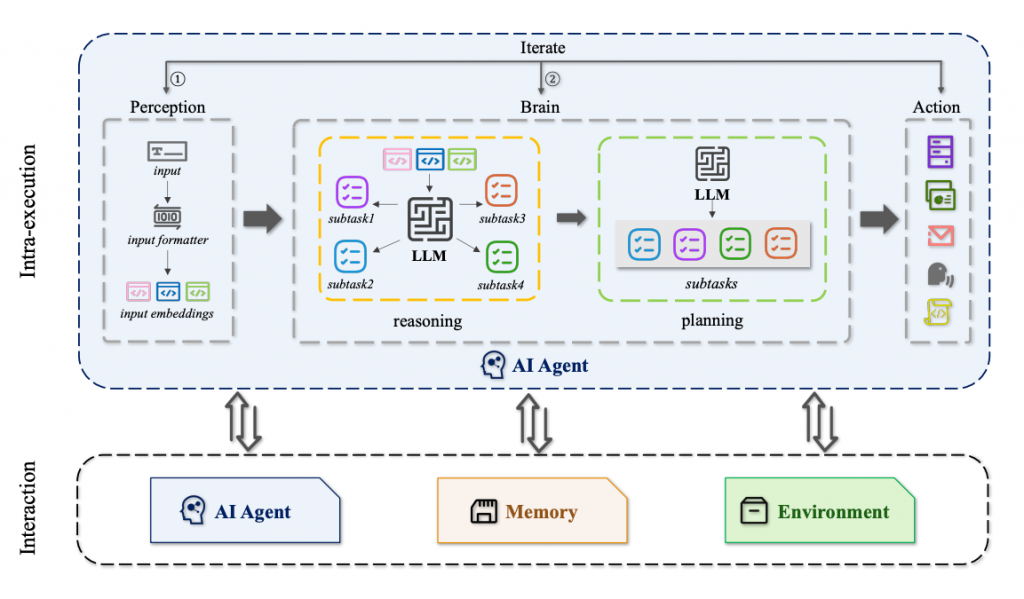
另外,在上图里也可以很直观的看到我们将外部资源(相较于Agent自身)细分成了其他AI Agent,Memory以及Env等不同组件,这也是根据观察现有的AI Agent结构以及常见的可能出现安全问题较多的位置划分出来的结构,每一部分都可能存在有一定的安全风险,同时有一些现有的研究已经表明了直接或者间接可能会影响到Agent的安全。
其实在文章里你能发现,我们将env部分细致的分为不同的情况:比如虚拟环境和真实的物理环境,前者包含了比如沙盒,以及Agent在虚拟环境中进行测试的这种场景的安全问题;另外真实的物理环境则包括比如带有传感器的Agent应该怎么有效接受和挑选外界的信息,如何屏蔽噪声,应该对外界信息作出怎样合适的反应和判断等等…
至于详细的内容可以参考原文,毕竟我们认为的精髓和要说的都已经在文章里吐露的差不多了。
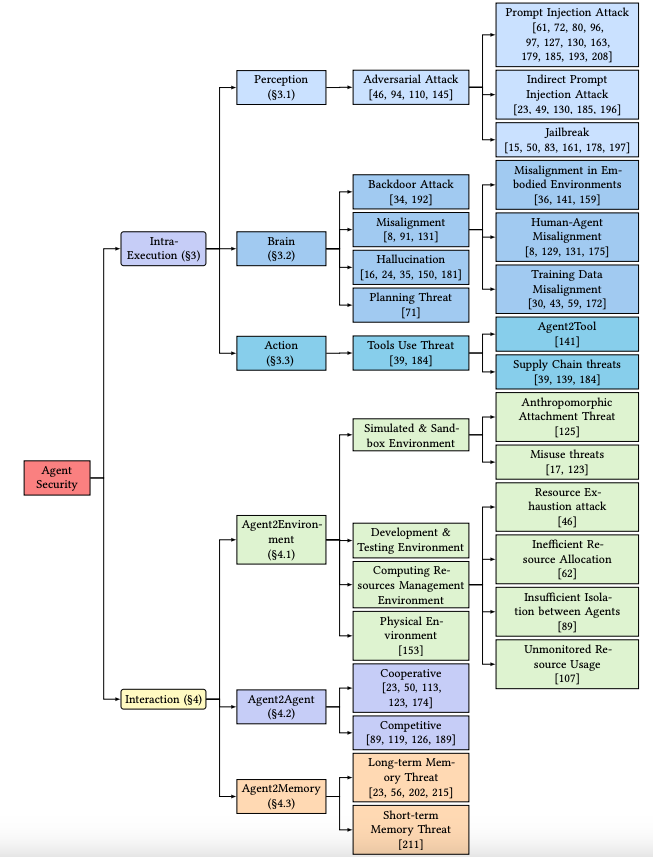
同时,AI Agent作为一个现在学术界和工业界都比较热门的话题,已经有大量的paper围绕着安全和隐私等话题进行展开,我们筛选了其中一部分最为具有代表性的绘制了思维导图如上,并且与本文的阶段以及行为划分进行匹配。
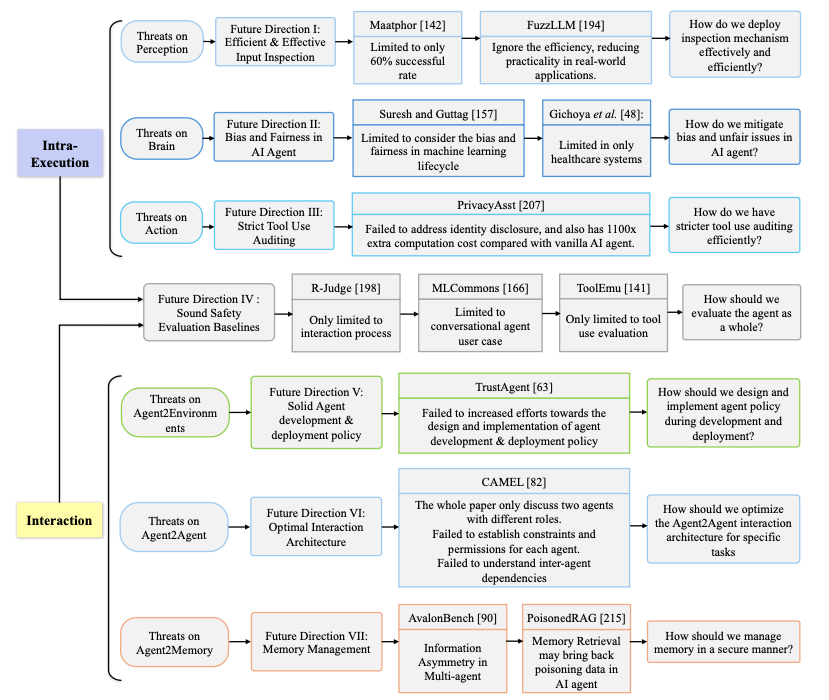
同时文章后面对未来的一些有价值有潜力的安全问题的研究点展开了探讨,我个人也是比较喜欢这个图。
同行的珍贵评价
悉尼的XAM(一家AI公司)夸了一下这篇文章,受宠若惊了哈哈哈哈哈,用词太… 令人脸红
另外 已经获得了本科隔壁西交一个团队的引用了:


