

ChatGPT说的不太准确,其实就是一个漏洞检测领域的数据集,里面存在有非常多种类的CWE漏洞的源码,可以用于分析二进制漏洞分析平台的漏洞检测能力。
该数据集在2012年推出了1.2版本,2017年更新到1.3并一直持续到本文发布日期,其使用文档包括1.2的介绍和1.3与1.2之间的区别两项文档,由于我主要使用四种CWE:78、415、416、476,因此看1.2的介绍即可。
1. 编译方法
对于Juliet,现我用过的编译方法共有三种
- 解压后顶级目录下
C/下可以直接make,这样编译出来的是一整个无后缀可执行文件Juliet1.3,其中会包含所有漏洞类型(当然windows-special的还是编译不了)。用IDA打开该文件,会发现每个漏洞文件都会单独变成一个函数。 - 顶级目录下
make individuals,会为每个编号的.c代码生成单独的.out可执行文件,以及每个文件对应的.o。 - 我之前用过的办法,进入每个子目录下
make,会报错,需要修改makefile,且只会生成.o
tip:由于我们只需要四种漏洞,因此前两个方式需要修改 testcasesupport/ 下的 main_linux.cpp 文件,如下代码段,筛选所需的漏洞即可:
# del_lines.py
with open('./main_linux.txt','r') as r:
lines=r.readlines()
with open('./main_linux1.txt','w') as w:
for l in lines:
if 'CWE78' in l and 'CWE789' not in l:
w.write(l)
if 'CWE415' in l:
w.write(l)
if 'CWE416' in l:
w.write(l)
if 'CWE476' in l:
w.write(l)
if '#' in l:
w.write(l)
删除individuals中的多余代码和中间文件:
# del_files.py
import os
def del_files(path):
for root,dirs,files in os.walk(path):
for name in files:
if '.o' in name and '.out' not in name:
os.remove(os.path.join(root,name))
print('Delete files:',os.path.join(root,name))
if '.c' in name or '.cpp' in name or '.h' in name:
os.remove(os.path.join(root,name))
print('Delete files:',os.path.join(root,name))
if __name__=='__main__':
path1='Juliet12.6/testcases/CWE78_OS_Command_Injection/s01/'
path2='Juliet12.6/testcases/CWE78_OS_Command_Injection/s02/'
path3='Juliet12.6/testcases/CWE78_OS_Command_Injection/s03/'
path4='Juliet12.6/testcases/CWE78_OS_Command_Injection/s04/'
path5='Juliet12.6/testcases/CWE415_Double_Free/s01/'
path6='Juliet12.6/testcases/CWE415_Double_Free/s02/'
path7='Juliet12.6/testcases/CWE416_Use_After_Free/'
path8='Juliet12.6/testcases/CWE476_NULL_Pointer_Dereference/'
del_files(path1)
del_files(path2)
del_files(path3)
del_files(path4)
del_files(path5)
del_files(path6)
del_files(path7)
del_files(path8)
2. abcd文件的关系(解释了之前.o文件存在问题的原因)
.o到.out之间的过程——链接(Linking):将多个目标文以及所需的库文件(.so等)链接成最终的可执行文件(executable file) ,这明明很重要却被我忽略了。
同编号后带有abcd的文件在看源码和 IDA 下都是互相调用的关系,比如:
CWE415_Double_Free__malloc_free_long_65.c a函数调用b函数,而头文件没有声明。
他们需要编译成.out文件才会将多个.o链接起来,所以.o不能用于测试UFA。
3. 编译过程中的架构问题
常用架构x86_64,x86_32;arm64,arm32;mips ,x86_64架构已经编译结束,接下来应为arm32架构,最后mips即可,且每一种生成 whole 整个文件和 individuals 多文件。
思路:配置好 toolchain 的环境变量,修改文件中的MakeFile文件,包括顶级目录和子目录下的,之后再make即可。
具体实现:
ARM32架构我直接在清华镜像源下载的v11版本:Index of /armbian-releases/_toolchain/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
MIPS32下载的是龙芯开源社区里的:http://www.loongnix.cn/index.php/Cross-compile
下载后将bin/添加到环境变量即可
最后修改多个makefile文件如下图即可
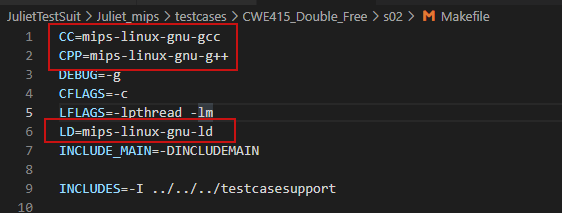
4. CWE规则统计
先看文档,漏洞信息
要点:
- Juliet中大多都是一个文件中存在两个函数bad和good,也包括我们挑选的4类CWE
- bad函数中一定存在漏洞,good函数则不存在漏洞
- badsink函数意为以不安全的手段调用数据源,goodsink则是安全的手段
- goodsource函数意为安全的数据源,badsource则为不安全的数据源
- goodG2B和goodB2G分别意为用不安全的手段调用安全数据,用安全的手段调用不安全数据,诚然,在日常使用中这样做会有风险,但是Juliet中这两种函数并不存在漏洞,为good
- 简言之,在漏洞检测平台检测结果的调用链项含有bad即确实检查到了存在漏洞的函数,含有good的函数意为误报。
- 由此,类似于AI的结果分析,这里也会存在TurePositive/FalsePositive/TureNegative/FalseNegative。
写了个shi山脚本:
import pandas as pd
path78 = "arm32/78.csv"
csv78 = pd.read_csv(path78)
print('There are ' + str(len(csv78)) + ' data lines in 78.csv')
csv78['Chain']
csv78['Path']
csv78['CWE']
TP78 = 0
FP78 = 0
CWE_n78 = 0
b = 0
g = 0
# analyse first line alone
if str(csv78['Path'][1]) != str(csv78['Path'][0]):
if 'bad' in str(csv78['Chain'][0]) and 'CWE-78' in str(csv78['CWE'][0]):
TP78 = TP78+1
if 'good' in str(csv78['Chain'][0]) and 'CWE-78' in str(csv78['CWE'][0]):
FP78 = FP78+1
if str(csv78['Path'][1]) == str(csv78['Path'][0]):
if 'bad' in str(csv78['Chain'][0]) and 'CWE-78' in str(csv78['CWE'][0]):
b = 1
if 'good' in str(csv78['Chain'][0]) and 'CWE-78' in str(csv78['CWE'][0]):
g = 1
# analyse line[1] to line[n-2]
for i in range(1, len(csv78)-1):
if 'CWE-78' not in str(csv78['CWE'][i]):
CWE_n78 = CWE_n78 + 1
if 'bad' in str(csv78['Chain'][i]) and 'CWE-78' in str(csv78['CWE'][i]):
b = 1
if 'good' in str(csv78['Chain'][i]) and 'CWE-78' in str(csv78['CWE'][i]):
g = 1
if str(csv78['Path'][i]) != str(csv78['Path'][i+1]):
TP78 = TP78 + b
FP78 = FP78 + g
b = 0
g = 0
# analyse line[n-1] (the end line)
if str(csv78['Path'][len(csv78)-1]) != str(csv78['Path'][len(csv78)-2]):
if 'bad' in str(csv78['Chain'][len(csv78)-1]) and 'CWE-78' in str(csv78['CWE'][len(csv78)-1]):
TP78 = TP78 + 1
if 'good' in str(csv78['Chain'][len(csv78)-1]) and 'CWE-78' in str(csv78['CWE'][len(csv78)-1]):
FP78 = FP78 + 1
if str(csv78['Path'][len(csv78)-1]) == str(csv78['Path'][len(csv78)-2]):
if 'good' in str(csv78['Chain'][len(csv78)-1]) and 'CWE-78' in str(csv78['CWE'][len(csv78)-1]):
g = 1
if 'bad' in str(csv78['Chain'][len(csv78)-1]) and 'CWE-78' in str(csv78['CWE'][len(csv78)-1]):
b = 1
TP78 = TP78 + b
FP78 = FP78 + g
amount78 = 288 + 287 + 192 + 192 # it's up to the true number of files | arm: 287->288
rateTP = TP78/amount78
rateFP = FP78/amount78
rate_CWE78 = CWE_n78/amount78
print('The File Number of CWE78 = '+ str(amount78))
print('TruePositive Number= '+ str(TP78))
print('FalsePositive Number= '+ str(FP78))
print('The Wrong CWE Number= '+ str(CWE_n78))
print('rateTP = '+ str(rateTP*100) + '%')
print('rateFP = '+ str(rateFP*100) + '%')
print('rate of Wrong CWE = '+ str(rate_CWE78*100) + '%')
大佬,我用你的方法改了linux_main.cpp,但是make的时候还是全编译了
谢谢你的阅读,最近两个月有些忙碌没太关心博客的事,如果还有问题或者需要交流的话,可以通过这个邮箱联系我:kisna.czhan@gmail.com
大佬,我用你的方法改了linux_main.cpp,但是make的时候还是全编译了
对应的Makefile也要修改
是的!谢谢兔子的回复~