
一、预备知识
1、 DIKW金字塔模型
先来说一说一些基本的抽象的概念-数据是什么?和信息,和人的关系?
DIKW金字塔模型揭示了“数据”与“信息”、“知识”和“智慧”等概念之间存在一定的区别与联系。

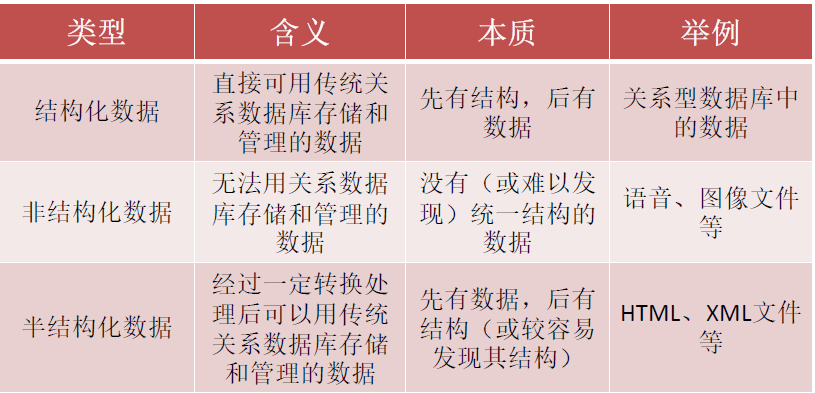
2、数据的分类
3、大数据是啥
大数据是指在云计算、物联网、智慧城市等新技术环境下产生的(新)数据的统称。
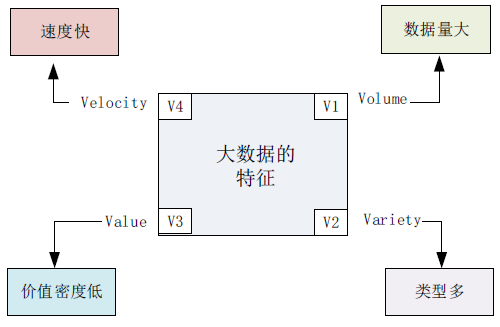
涌现:大数据与普通小数据的区别
- 价值涌现:大数据中的某个成员小数据可能“没什么用(无价值)”,但由这些小数据组成的大数据会“很有用(有价值)”
- 隐私涌现:大数据中的成员小数据可能“根本不涉及隐私(非敏感数据)”,但由这些小数据组成的大数据可能“严重威胁到个人隐私(敏感数据)”。
- 质量涌现:大数据中的成员小数据可能有质量问题(不可信的数据),如缺失、冗余、垃圾数据的存在,但不影响大数据的质量(可信的数据)。
- 安全涌现:大数据中的成员小数据可能不涉及安全问题(不带密级的数据),但如果将这些小数据放在一起变成大数据之后,很可能影响到机构信息安全、社会稳定甚至国家安全(带密级的数据)。
4、研究大数据目的?-数据科学?
数据科学的最终研究目标是实现数据、物质和能量之间的转换,即如何通过“数据的利用”方式降低“物质、能量的消耗”或(和)提升“物质及能量的利用效果和效率”。
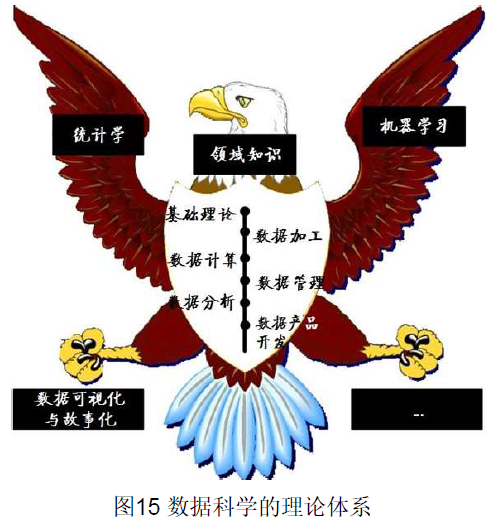
数据科学10大基本原则?

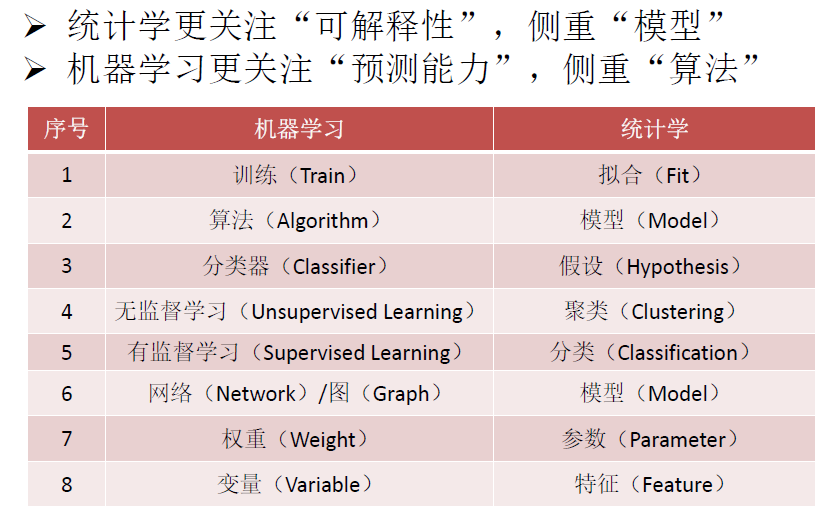
5、统计学思想-分析方法

元分析:
元分析法是一种在已有统计分析结果的基础上进一步进行统计分析的方法。
用于对“高层数据(二次或三次数据)”,尤其是对基本分析法得出的结果进行进一步分析的方法。
与机器学习的关系
6、机器学习(仅提KNN、遗传算法和强化学习)
1)KNN:给输入者挂上已知标签的分类算法
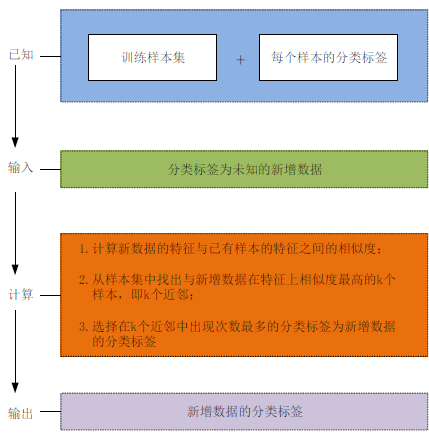
关键:“计算新增数据的特征与已有样本特征之间的相似度”
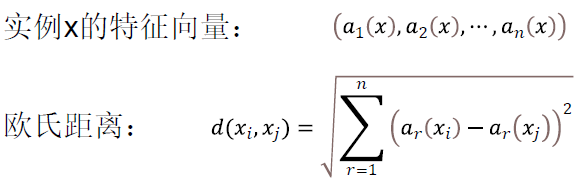
2)遗传算法(GA)
主要研究问题:
- 从候选假设空间中搜索出最佳假设
- 最佳假设指“适应度(Fitness)”指标为最优的假设
- “适应度”是为当前问题预先定义的一个评价度量值

3)强化学习
给出不同老师的解释方式和我的理解

二、数据科学
1、基本流程
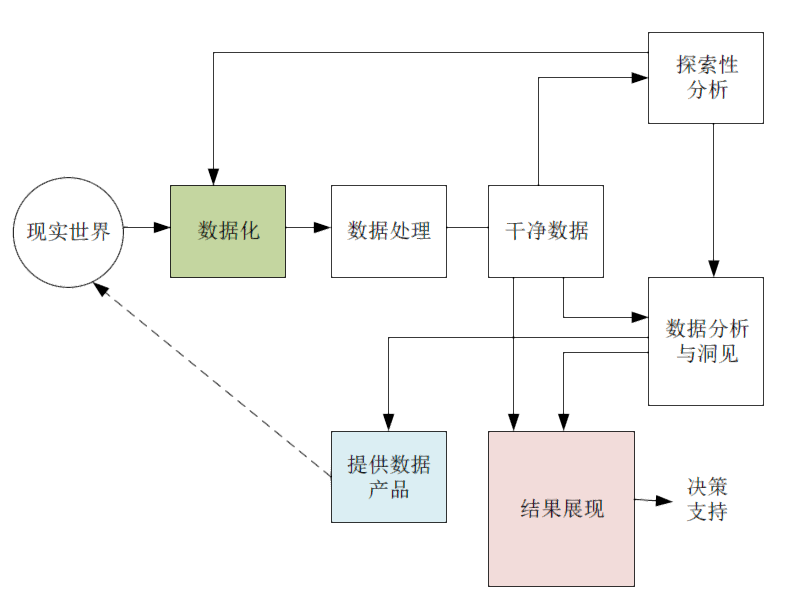
2、数据审计




3、数据分析技术
1、MapReduce
定义:
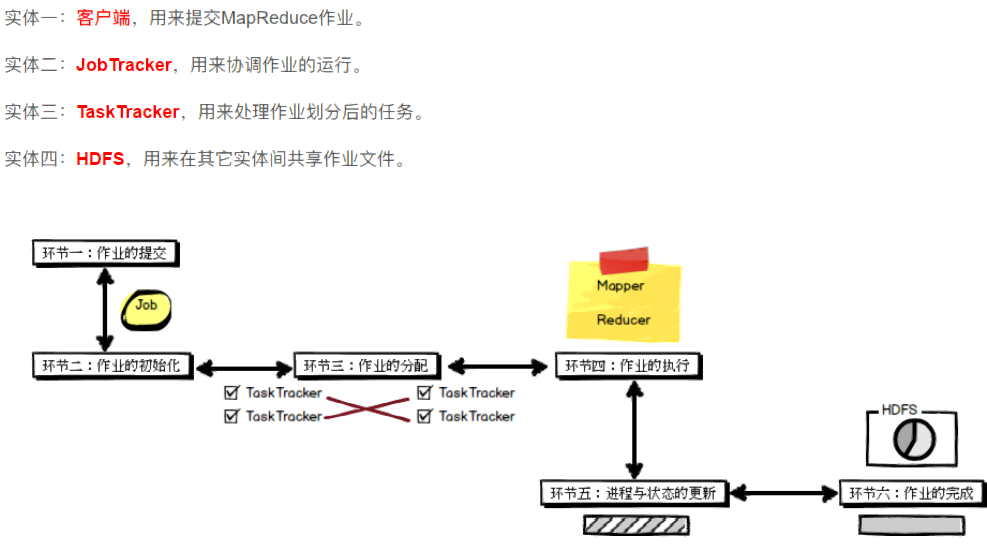
MapReduce是一个软件框架,基于该框架能够容易地编写应用程序,这些应用程序能够运行在由上千个商用机器组成的大集群上,并以一种可靠的,具有容错能力的方式并行地处理上TB级别的海量数据集。
软件框架,并行处理,可靠且容错,大规模集群,海量数据集。
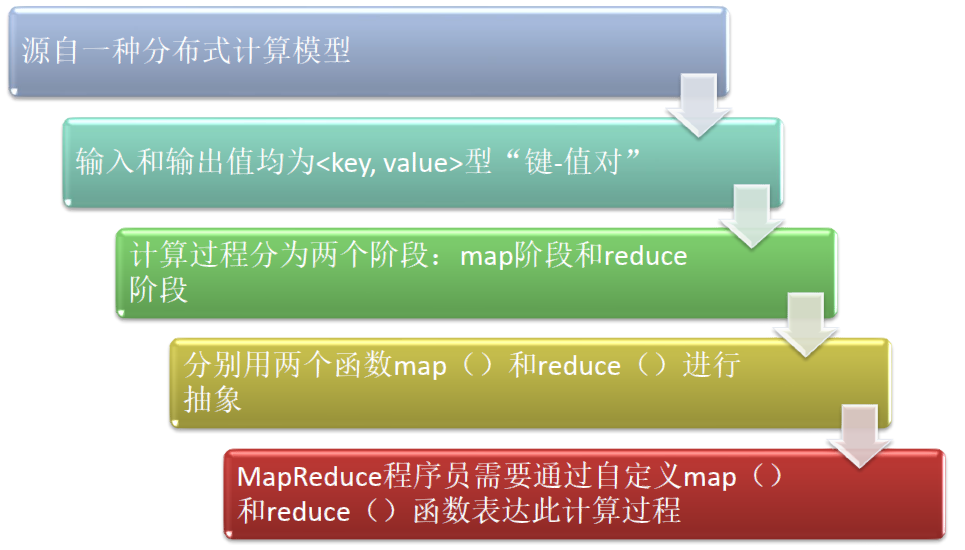
MapReduce的思想就是“分而治之”。
(1)Mapper负责“分”,即把复杂的任务分解为若干个“简单的任务”来处理。“简单的任务”包含三层含义:
一是数据或计算的规模相对原任务要大大缩小;二是就近计算原则,即任务会分配到存放着所需数据的节点上进行计算;三是这些小任务可以并行计算,彼此间几乎没有依赖关系。
(2)Reducer负责对map阶段的结果进行汇总。至于需要多少个Reducer,用户可以根据具体问题,通过在mapred-site.xml配置文件里设置参数mapred.reduce.tasks的值,缺省值为1。
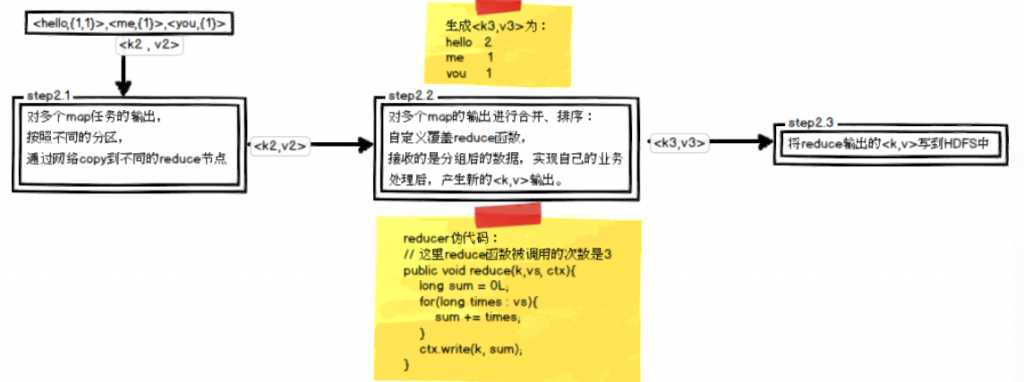
Map:

reduce:
应用:

特征:

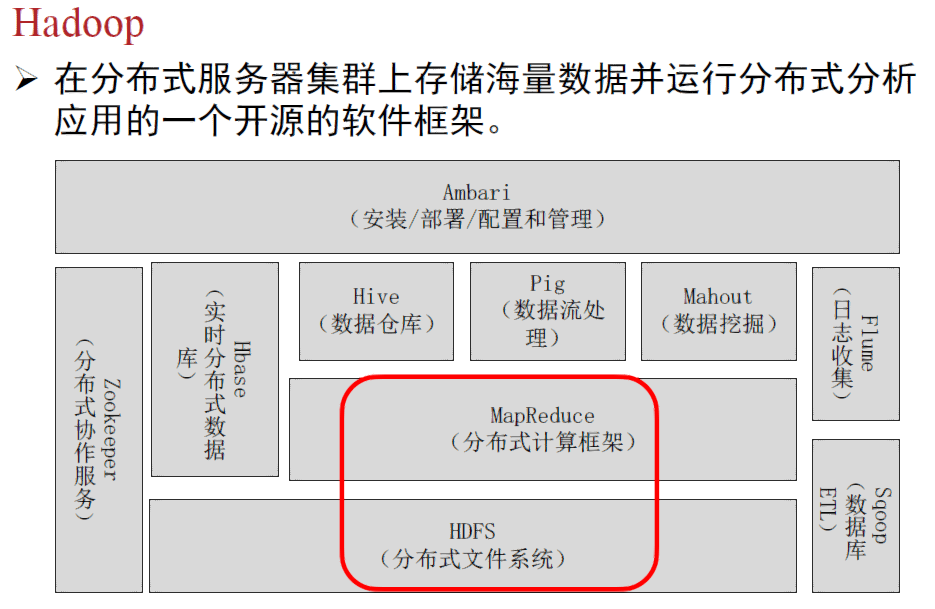
2、Hadoop
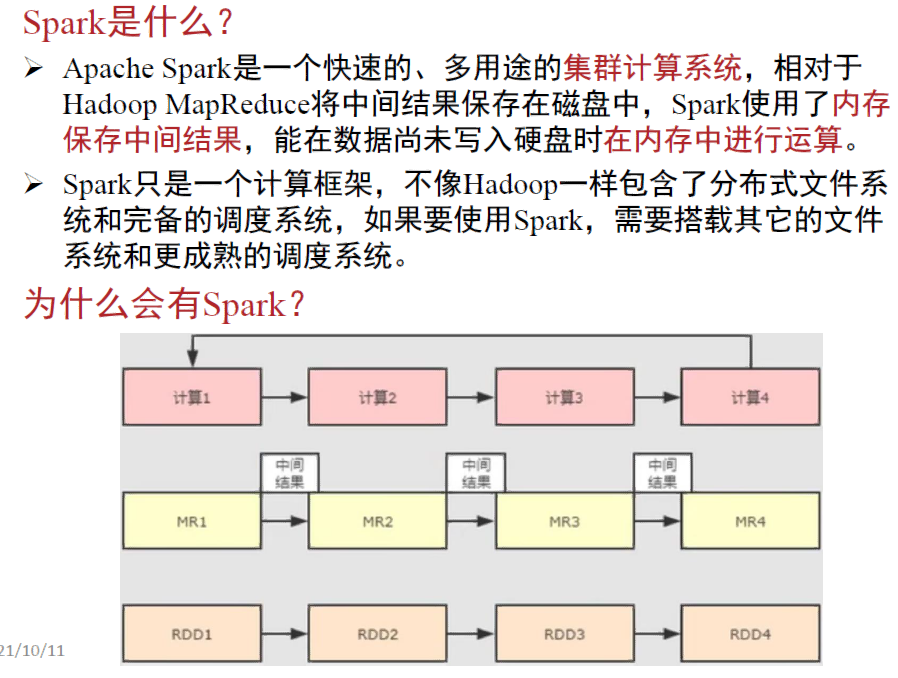
3、Spark




4、SQL
略
